How To Designing A Faster Than Faster GitHub Monitoring System
0x00 为什么需要这样的系统
近些年来,特别是2018年,各种不同的Github监控工具层出不穷,究其原因,还是每家企业生怕安全意识不足的员工将内部代码、账号信息上传至Github中,导致一些严重的安全问题,很有可能我们费劲千辛万苦构筑的边界防线,就被一个开发人员轻松的打破了。
目前市面上有许多种Github监控工具以及系统,有命令行的,有带界面的,有直接爬Github搜索页面的,也有借用API来搜索的,经过一些调研,发现各有特色,但是对于“开箱即用”等要求上,可能略有些距离。
本人在上家公司时,也曾负责过Github监控系统的开发与运营,经过很长时间的摸索,也总结了一些经验以及思路,并实现出了本文的主角GEYE监控系统(Github Eye)。在之前公司,Github监控系统应该说是经历了多次迭代,从最早的单文件脚本,逐步升级成了一个可视化的精确Github信息捕获系统,也多次先于白帽子发现了Github上的敏感信息,以及很多没有被外部发现的敏感信息。最快可在敏感信息被上传15分钟内捕获发现。
0x01 简谈设计思路
1. 整体设计思路
整体思路其实非常简单,就像把大象放到冰箱里一样,只有三步:
- 从Github获取我们感兴趣的信息
- 人工/自动筛选、过滤
- 入库并通知相关人员/系统
但是在每一步中,我在实现的时候,均会遇到一些比较坑的问题,也选取了不同的方案做了一些实验,最终得到了一个比较符合我预期的最佳方案,下面来简单介绍一下。
2. 获取信息
监控的第一步当然是要获取信息,获取信息的方式有很多,目前开源的监控系统里,有直接使用爬虫爬取搜索页面的,也有调用API的,当然我这里推荐的做法是调用官方的API来获取原始数据,说实话我不是很理解一些项目中通过直接爬取搜索页面获取数据的方式,也没有想到这样做有什么优势,甚至印象中好像还有某个项目为了避开Github的爬虫来源IP检测,还用Nginx搭建了一个反向代理集群来解决。所以我认为直接爬取搜索页面不是一个十分优雅的做法。
那么我们就剩下一条路可以选了,那就是利用Github提供的APIv3来获取原始数据。因为目前APIv4还不支持搜索代码,如果未来支持了,GEYE也许会切到APIv4上。
我们先来看一下搜索代码的API文档:https://developer.github.com/v3/search/#search-code
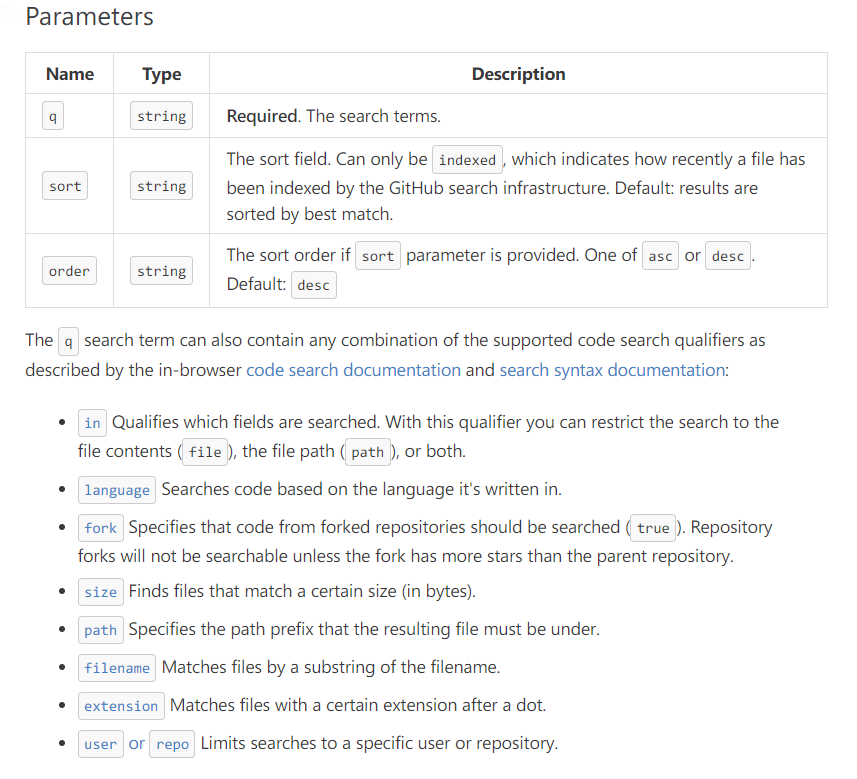
怎么用这里就不说了,相信大家都会用,我们只说一说需要注意的问题。首先这个q参数就是我们想查询的关键字,比较好理解,但是我们除了要添加关键字之外,还要额外添加一些参数,那就是fork,这个参数是用来指定“是否搜索fork”仓库的,如果这个值为true,那么这个接口会返回来自fork的仓库的数据,如果某个很著名的仓库(例如fastjson)中命中了你的关键字,那么你可能会拿到无数的重复信息,这不是我们希望看到的;我们希望的是尽可能多的获取不同仓库的信息,而不是同样的内容返回一万遍。
另外一点,我们其实希望尽可能快的获取到“新鲜”的泄露信息,所以我们还要修改这个接口的默认排序方式。默认情况下,Github会为我们返回最匹配的结果,无论这个代码是什么时候被上传的。所以我们需要指定sort参数。
结合起来,我们最后的请求参数可能是这样的:/code/search?q=keyword+fork:false&sort=indexed
说完关键字之后,应该就可以开始写爬虫调用API了,但是这里还有一点,Github为了防止我们滥用API,会有频率限制。正常情况下,每个Personal Access Token的频率是每分钟可以请求30次API接口,如果调用过快,会触发滥用警告,就是会限制你的token 1分钟。如果是通过OAuth2授权的App级别的token,请求上限会高很多。
基于这样的限制,我们没必要去优化我们的爬虫让他爬的很快,因为同样时间下,调用的频率是被限制好的。我们只需要利用普通的多线程爬虫获取数据即可。
3. 筛选信息
当我们将数据取回后,就需要决定哪些数据需要被人工确认,或是直接确认,哪些数据需要被丢弃。当然一股脑的将所有代码全都交给人工来判断也不是不可以,只要你的精力足够。
我们当然希望系统能够自动帮我们过滤掉一些无用的数据才好,我们人工只关心最有可能是泄露的部分,那么这就要考验我们的筛选模块了。
一开始,我是以API接口返回的代码段作为“基础值”,来进行过滤的,但是后来发现,接口返回的代码段里,其实并不会完全包含你的关键字。举个例子,比如你搜索的是corp.lightless.me,但是返回的代码段中,可能更多的是包含了corp、lightless、me三个分开的单词的结果,这也为我们过滤信息造成了一定的困扰。
再举一个例子,我们搜索的内容是lightless.me+password,那么返回的代码段中,很有可能只包含lightless.me的结果,而关于password部分的代码段没有被返回回来,这样情况过滤的时候,就有可能漏掉了。
为了避免这些情况,我的解决方法可能有些蠢,就是利用返回的信息,拼出raw.githubusercontent.com对应的代码文件,将其拉取回来,作为代码部分过滤的基底,这样的情况下可能相对来说会更准确一些。

需要过滤的内容不只是代码内容,还有username、repoName、filename、path等,也需要作为自动过滤的考量。至于为什么,大家可以自己尝试探索一下。
4. 存储信息
对于存储信息来讲,其实没有什么好说的了,关键问题在于如何去重。Github天生的sha值就是一个很好的去重参考值。我们考虑下面这样一个场景:
如果某个文件,第一次被处理的时候,出现了敏感信息,并且入库保存;
当文件更新了新的敏感信息后,这时候如果以文件名、仓库名等信息去重,就会认为已经和库内的信息重复了,无法正常入库,导致我们错过了重要的信息。
而每个文件都具有一个sha值,当文件变动的时候,这个值也会跟着变动,所以我们不用去费劲心思设计去重的指标,利用这个sha值就好了,这也是API接口会返回给我们的数据之一。
0x02 规则系统设计
规则系统应当算是这个系统的核心以及亮点,设计了一套自认为比较完善的搜索规则加过滤规则系统。整体来看,规则系统分为三大部分,分别是:搜索规则,过滤规则,全局过滤规则。
1. 搜索规则
搜索规则比较容易理解,其实就是搜索的关键字,用于初筛数据。每个搜索规则会含有多个过滤规则,用于第二层过滤数据。搜索规则的话,一般是搜索某个企业的内网域名,这样搜到敏感信息的命中率会比较高一些,比如corp.example.com,inner.example.com,example.net,example.org等等,每家公司都有自己的内网域名定义方式,如果是白帽子,可能就需要细心收集了。
当然这里也是有一些trick的,根据Github的搜索文档,会发现有全字匹配的搜索方式,即用双引号把关键字包起来:"corp.example.com",这样搜到的内容中会大部分含有完整的域名,而不是分开的三个单词,在实际使用的时候,是使用全字搜索还是非全字搜索,这都要针对不同的情况进行选择了。
2. 过滤规则
这就是第二层的具体过滤规则了,用于从初筛回来的数据中提取敏感信息、过滤垃圾信息等等。我在这里设计的时候,支持两种方式,字符串匹配以及正则,对于一些简单的情况,就可以直接利用字符串code.contains("keyword")的方式来匹配,当需要进行复杂的过滤的情况,就可以使用正则来匹配,比如(token|password|passwd|access[_]*key|secret[_]*key)["']*\s*(\=|\:)这种情况。
设计字符串匹配的原因还有一点,就是因为Python本身的正则匹配存在一些坑点。有时候会搜到一些.json文件,而这个文件只有一行,大小一般在几十KB上下,这时候Python的正则匹配会非常的慢,甚至导致DoS问题,进而整个过滤线程都卡死了,影响到整个系统的正常运行。
所以这里我在设计的时候,除了使用Python内置的正则,还调用了grep命令来解决这个问题,这样虽然会额外消耗一些新开进程的资源,但是整体来说会相对稳定一些。
3. 全局过滤规则
全局过滤规则,顾名思义,就是作用于所有搜索规则的过滤规则,为什么要这样做呢?想必做过Github信息泄露监控的同学会遇到过这种问题,搜索到的内容经常是一些垃圾信息,但是非常具有通用性,比如example.github.io的仓库名,这些一般都是静态博客,里面的一些html中经常误报。甚至是其他的html文件也会经常误报。对于这种情况,如果为每一条搜索规则都添加过滤规则的话,会十分重复。如果有上百条搜索规则的话,加起来怕是要累死。所以我设计了一个全局过滤规则,这样就可以在真正的进行过滤前,过滤掉一些无用的数据。
0x03 重点监控规则
很多时候,我们除了需要定时搜索敏感信息外,可能还想定时监控某个仓库、某个用户的行为,是不是上传了某个敏感文件,FastJSON是不是又有了安全更新,如果可以拿到这些信息,那么在对于我们研究一些组件的安全性、还是定点监控某个仓库、用户的行为,都有很大的帮助。
为此,特意为GEYE添加了重点监控功能,是基于Github的Events机制来完成的。
举几个可能会用到的场景:比如我需要监控FastJSON仓库的每一次push行为,来及时的获取更新内容,看看是不是有安全更新,如果有安全相关的更新,那么可以马上diff代码,查找相关可能出现漏洞的地方,并且及时的在公司内部安排新版本修复计划。另一方面,也可以分析出最新的PoC,添加到扫描器中扫一波。
还有些时候,发现了某用户或某仓库,出现了疑似敏感信息,例如内部数据库的账号密码,但是无法完全确定。或者是需要监控公司开源的仓库项目是否会出现敏感信息的情况。这个时候可以利用重点监控功能监控该仓库或该用户,一旦该用户提交了新的代码,可以马上发现,并进一步进行排查。可能有同学会问:就算他提交了敏感信息,普通的通过API搜索不也会发现吗?答案是确实可以,但是这里涉及到了一个时效性的问题。
纵观市面上的全部Github监控,细心的你一定可以发现,无论是多么优秀的工具(包括GEYE),都无法做到实时的发现,即便是无搜索间隔和无限的Token,永远都存在一个10~15分钟的延迟。也就是说,当你push了代码到Github上,都需要10~15分钟后,你这份代码才可以被通过API搜索到。个人猜测这个延迟是Github本身对新提交的代码进行索引的时间,只有被Github索引过的代码,才能够通过API搜索到。而对于events来说,则不存在这个限制,当用户的push操作完成后,就会产生一个PushEvent,不存在很明显的延迟(除非你监控的是public event,这个有5分钟的延迟)。所以重点监控功能,既可以弥补一些时间上的问题,也可以做到对单个用户、仓库的精确打击,还可以和公司业务结合,精准监控开源项目。
目前仅仅实现了针对PushEvent和ReleaseEvent事件的监控,后续计划支持更多的事件类型。
0x04 未来发展计划
GEYE作为一款真正意义上的“企业级”监控系统还差的比较远,当然也是在不停的完善之中。对于这个系统的未来发展,有一些不成熟的想法,可以先写出来,立个flag,看看后面会不会实现起来。
在开始之前本来以为是个小项目,但是越写越大了,这个坑怕是填不好了。GEYE GITHUB 传送门
- Server/Agent拆分,可快速横向扩展Agent
- 重点监控的内容支持规则过滤,只保留命中规则或未命中规则的事件
- 更多暂时未想到的功能
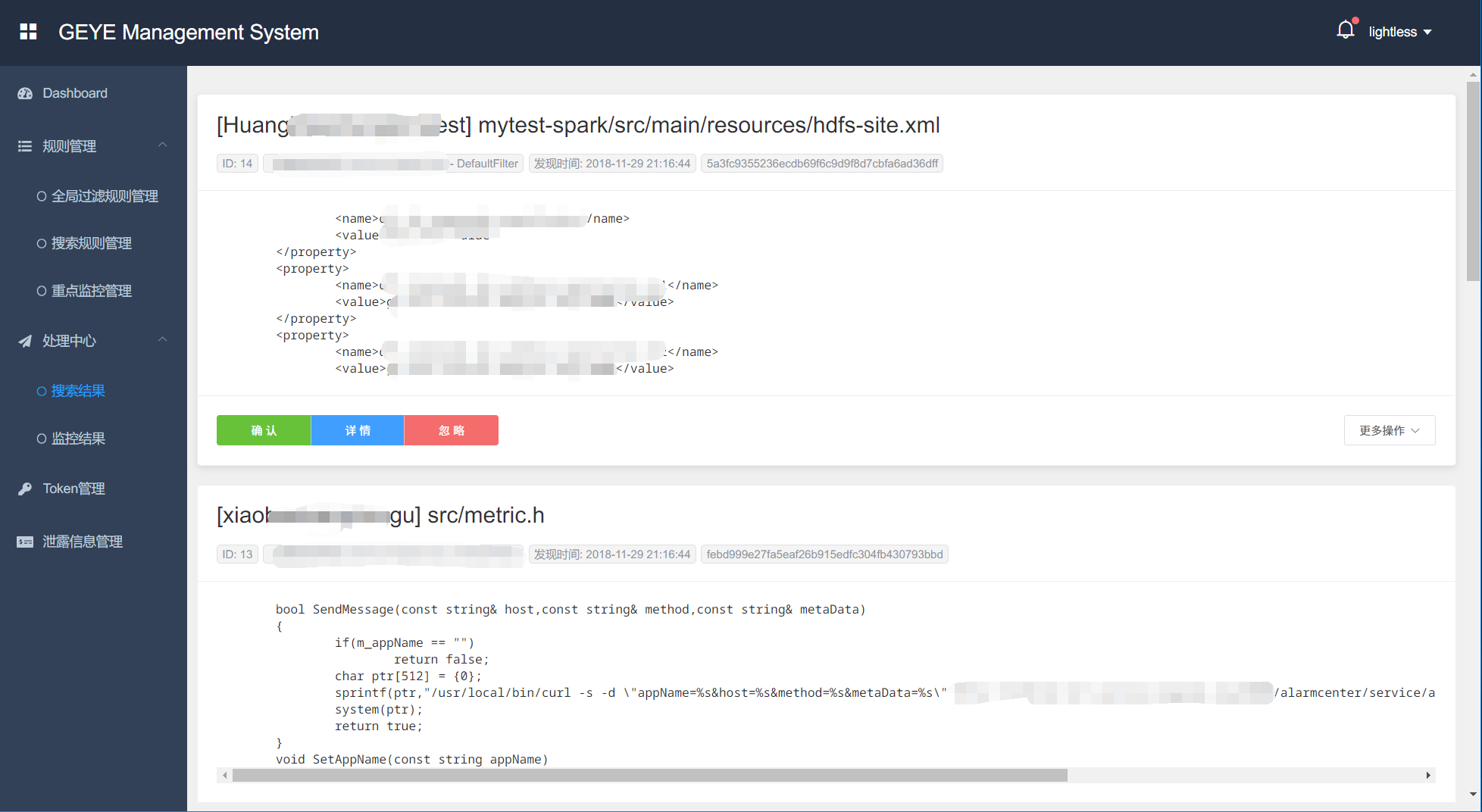
目前已经完成了第一个release版本,由于是利用业余时间更新的,所以迭代可能会非常慢,一天也只能修一个bug、加一个小feature而已。最后贴一张目前的效果:


CRLF-Header:CRLF-Value
%0d%0aCRLF-Header:CRLF-Value
\r\nCRLF-Header:CRLF-Value
'+(40060*44528)+'