Python协程之从放弃到死亡再到重生
前面一篇关于Python协程的文章中,提到了python中协程的一些历史以及一些简单的用法,这些用法放在实际开发中可能不太够,我在后面的编写中就踩到了不少的坑,这里就回应上篇文章中末尾说的,再写一篇文章来梳理一下这些问题。时隔很久,终于还是磨磨唧唧的把第二篇写出来了。本来还准备有第三篇重生篇的,但是以防拖稿,合并到一起来写吧。
0x00 又是生成器?
我们已经知道了,生成器可以作为协程来使用,但是很多细节问题尚未明确,我们先从最简单的一个协程开始。(后面会出现"生成器"和"协程"两个词混用的问题,可以都理解为"作为协程使用的生成器")
def easy_coroutine():
print("Start!")
x = yield
print("End! x: {}".format(x))
这就是最简单的协程了,如果想使用这个协程,看起来还是有点麻烦的:
# lightless @ LL-DESKTOP in C:\Users\lightless\Desktop [20:40:27]
$ python -i .\ez_coroutine.py
>>> c = easy_coroutine()
>>> c
<generator object easy_coroutine at 0x0000016AD411E570>
>>> next(c)
Start!
>>> c.send(666)
End! x: 666
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
创建协程的方式与创建生成器一样,通过调用函数的方法获取到一个生成器对象。紧接着调用next()方法来启动生成器,这一步也称为prime,有些文章会把这个东西翻译成"预激",即让协程开始执行到第一个yield表达式的位置。(为了方便下文都称为预激了)
下面又调用了c.send(666),调用者方法后,x = yield表达式就会得到666这个值,然后协程恢复运行,直到协程结束或者遇到另外的yield表达式为止。当然这里最后会抛出一个StopIteration异常,因为代码执行完毕了,这就是生成器的标准行为,不用在意。
在这个执行过程中,会发现我们的easy_coroutine()经历的多个状态,并非总是一直处于RUNNING的状态。事实上,协程的状态有四种:GEN_CREATED,GEN_RUNNING,GEN_SUSPENDED,GEN_CLOSED。这四种状态分别是等待开始执行,正在执行,停在了yield表达式位置,执行结束。如果你想获取某个协程的当前状态,可以通过inspect.getgeneratorstate函数获取。
额外说明一点,
send()方法的参数会传递给协程,作为yield表达式的值,所以只有当协程处于GEN_SUSPENDED的状态时,才可以调用send()方法传递值。如果协程还没有prime,那么可以通过调用send(None)来预激协程。啥,你问为什么不能通过给尚未prime的协程调用send(233)来预激协程,如果你试过的话就会收到一个TypeError。
每次预激协程的时候都需要调用一遍next()函数,很麻烦,而且很容易忘掉,一旦忘记预激协程,后果也是十分严重的,因为没有被预激的协程没有任何作用。有没有简单的方法让Python自动预激协程呢?有的,函数装饰器就可以做到这一点,于是我们可以自己封装一套来让其自动预激!
def prime_coroutine(func):
@functools.wraps(func)
def prime(*args, **kwargs):
t = func(*args, **kwargs)
next(t)
return t
return prime
代码十分简单,如果看不懂的话,建议先去学习一下Python的装饰器部分。可能各位很容易想到之前提到过的一种装饰器,在Python3.4以后,标准库中新增了asyncio.coroutine装饰器,用于修饰协程函数,但是非常遗憾,这个装饰器并不会预激协程,而通过yield from语法调用一个协程时,会自动预激。所以可以通过asyncio.coroutine和yield from配合使用,实际上我们也是这样使用的。
这里有人会问,如果在写成中抛出了异常怎么办,是不是和普通函数的异常一样?当协程中出现异常时,而协程本身又没有捕获处理,那么这个异常会"冒泡"至协程的调用方,即next()或send()函数的调用方。如果协程已经抛出了异常,再尝试去调用它,会得到一个StopIteration异常。于是有人发现了可以通过让协程抛出异常的方式终止一个协程的运行。确实没错,而且我们也确实可以通过generator.throw()和generator.close()显示的向协程发送异常,使协程停止。这里举个例子:
def exception_handler_example():
print("Start!")
while True:
try:
x = yield
except TypeError:
print("Receive type error!!")
else:
print("Receive value: {}".format(x))
print("End!")
看一下运行样例
# lightless @ LL-DESKTOP in C:\Users\lightless\Desktop [21:43:06]
$ python -i .\ez_coroutine.py
>>> c = exception_handler_example()
>>> next(c) # 预激协程
Start!
>>> c.send(666)
Receive value: 666
>>> c.send(TypeError)
Receive value: <class 'TypeError'>
>>> c.send(777)
Receive value: 777
>>> c.close()
>>> c
<generator object exception_handler_example at 0x000001499EECEA40>
>>> from inspect import getgeneratorstate
>>> getgeneratorstate(c)
'GEN_CLOSED'
>>>
这个协程是一个死循环,不停的接受调用方的值并且打印出来,有三个地方需要留意一下。
- 最后的End字符串始终没有打印出来。因为只有没有被捕获的异常会终止这个死循环,然而矛盾的是如果出现了未处理的异常,那么协程就挂了,所以不会输出最后的End字符串。
- 当调用
c.close()时,会使生成器的yield表达式部分抛出一个GeneratorExit异常。如果生成器本身没有处理这个异常,或者运行到了生成器的结尾(即抛出了StopIteration)的情况下,调用方不会出现任何错误。另一方面,如果生成器收到了GeneratorExit异常,那么生成器就无法生成值! - 当
send(TypeError)时,并不会终止生成器的运行,这一点很容易理解。
当c.close()后,我们获取协程的状态,确实是已经处于执行结束的状态了。
如果调用
c.throw()方法,则会在yield表达式那里抛出一个指定的异常,如果生成器捕获并且处理这个异常,那么生成器会继续向下执行到下一个yield表达式的位置。如果生成器没有捕获这个异常,那么异常就会向上"冒泡",传递给生成器的调用方。
0x01 yield进化!
前面提到过,Python后来添加了yield from语法,之所以要引入这种东西,有两种原因,"把异常传入嵌套协程问题"和"让协程更好的处理返回值问题"。
可能有人已经发现了,我们定义的协程并不会return值,只会通过yield生产值。我们下面写个例子,这个协程不会"产出"值,而是"返回"值。
def sum():
total = 0
nums = []
while True:
x = yield
if not x:
break
total += x
nums.append(x)
return total, nums
运行一下看看。
# lightless @ LL-DESKTOP in C:\Users\lightless\Desktop [21:58:28]
$ python -i .\ez_coroutine.py
>>> s = co_sum()
>>> next(s)
>>> s.send(666)
>>> s.send(233)
>>> s.send(1)
>>> s.send(None)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration: (900, [666, 233, 1])
>>>
我们通过发送None来终止这个协程的运行,虽然抛出了StopIteration异常,但是异常对象的value部分存有return语句的返回值。我们稍微修改一下调用方法,让这段代码看起来不那么奇怪:
# lightless @ LL-DESKTOP in C:\Users\lightless\Desktop [22:00:59]
$ python -i .\ez_coroutine.py
>>> s = co_sum()
>>> next(s)
>>> s.send(1)
>>> s.send(2)
>>> s.send(3)
>>> try:
... s.send(None)
... except StopIteration as e:
... result = e.value
...
>>> result
(6, [1, 2, 3])
>>>
虽然看起来不是很奇怪了,但是从异常对象中获取协程的返回值显得有点难过。为啥这么做呢?我们稍微考虑一下,生成器执行结束后的常规行为是什么?抛出StopIteration异常!那么要想办法把值从协程内部传出来,似乎唯一的方式就是放在异常对象的值中了。更难过的是,这是PEP 380定义的方式。前面提到过,yield from语法结构要解决的问题之一就是"让协程更好的处理返回值问题",所以"yield from"的一个行为就是会在内部自动捕获StopIterator异常,并且将异常对象的value属性设置为yield from表达式的值。
如果你以为yield from的作用就这些的话,那可是大错特错了,他比yield的功能更加强大,作用也多很多。它的主要功能类似于一个"通道"或者一个"委托器",用于将协程的调用方和嵌套协程最内层的子生成器连接起来,让二者可以愉快的发送和生产值。PEP 380中添加了一些新的术语,我们沿用一下。
- 委托生成器(delegating generator):包含
yield from <iterable>结构的生成器函数。 - 子生成器(subgenerator):从
yield from表达式中iteratable部分获取的生成器。(有时候就叫iterator,23333)
我们来看一个使用了yield from的例子,看起来有点复杂,而且很难受,因为是为了使用yield from刻意编出来的代码。
final_result = {}
def co_sum():
total = 0
nums = []
while True:
x = yield
print("co_sum receive: ", x)
if not x:
break
total += x
nums.append(x)
return total, nums
def middle(key):
idx = 0
while True:
print("middle idx: ", idx)
final_result[key] = yield from co_sum()
print("sub-generator co_sum() done.")
idx += 1
def main():
data_sets = {
"set_1": [233, 666, 123],
"set_2": [1, 2, 4, 5],
"set_3": [999, 999, 999],
}
for key, data_set in data_sets.items():
print("start key:", key)
m = middle(key)
next(m) # 预激middle协程
for value in data_set:
m.send(value) # 给协程传递每一组的值
m.send(None)
print("final_result:", final_result)
if __name__ == '__main__':
main()
这段代码作用是,计算三个数值集每一个集合的总和,运行结果如下,我们依次来看每个函数的作用。
# lightless @ LL-DESKTOP in C:\Users\lightless\Desktop [22:51:54]
$ python yield_from.py
start key: set_1
middle idx: 0
co_sum receive: 233
co_sum receive: 666
co_sum receive: 123
co_sum receive: None
sub-generator co_sum() done.
middle idx: 1
start key: set_2
middle idx: 0
co_sum receive: 1
co_sum receive: 2
co_sum receive: 4
co_sum receive: 5
co_sum receive: None
sub-generator co_sum() done.
middle idx: 1
start key: set_3
middle idx: 0
co_sum receive: 999
co_sum receive: 999
co_sum receive: 999
co_sum receive: None
sub-generator co_sum() done.
middle idx: 1
final_result: {'set_1': (1022, [233, 666, 123]), 'set_2': (12, [1, 2, 4, 5]), 'set_3': (2997, [999, 999, 999])}
main()函数通过循环分别读取每一个集合的key和一个存有多个数字的list。然后生成一个middle()协程并预激,将列表中的每一个数字通过send方法发过去。发送完毕后调用send(None)结束协程的运行。middle(key)函数其实是一个委托生成器,因为他含有一个yield from <iterator>结构。这个循环每次遍历的时候,会生成一个新的co_sum()实例,每个实例都是一个生成器,当然是作为协程使用的生成器对象。委托生成器会在yield from的时候暂停执行,将控制权交给co_sum(),并等待co_sum()执行结束。co_sum()函数是一个子生成器,与上一个例子中的代码一样。
现在再回过头来看这段代码,就比较容易理解了,这里只有一个子生成器和一个委托生成器,如果我们将子生成器换成一个委托生成器,再通过yield from调用其他的子生成器,就可以将任意多个生成器链接起来,只要最终的子生成器通过yield表达式结束即可。
0x02 何为yield from
本节内容较为枯燥无味,如果不感兴趣,可以跳过本节
是时候来深入理解一下yield from这个结构了,根据PEP 380来看,这东西相当难理解,而且及其复杂。下面我们就来试着解释一下RESULT = yield from EXPR。我们先把问题简化一下,做出以下几个假设。
- 假设
yield from出现在委托生成器中,并且由调用方调用,同时也驱动着子生成器。 - 假设不支持
.throw()和.close()方法。 - 假设生成器不会抛出异常,而是执行到代码最后,直到抛出
StopIteration异常为止。
在这些假设下,RESULT = yield from EXPR可以简化成下面这样,在读这段代码之前,我们先说明一下这些下划线开头的变量的作用:
- _i:子生成器,同时也是一个迭代器
- _y:子生成器生产的值
- _r:yield from表达式最终的值
- _s:调用方通过
send()发送的值 - _e:异常对象
这段代码的大部分含义已经在注释中说明了,可以结合注释来理解这段代码的含义。
_i = iter(EXPR) # EXPR是一个可迭代对象,_i其实是子生成器;
try:
_y = next(_i) # 预激子生成器,把产出的第一个值存在_y中;
except StopIteration as _e:
_r = _e.value # 如果抛出了`StopIteration`异常,那么就将异常对象的`value`属性保存到_r,这是最简单的情况的返回值;
else:
while 1: # 尝试执行这个循环,委托生成器会阻塞;
_s = yield _y # 生产子生成器的值,等待调用方`send()`值,发送过来的值将保存在_s中;
try:
_y = _i.send(_s) # 转发_s,并且尝试向下执行;
except StopIteration as _e:
_r = _e.value # 如果子生成器抛出异常,那么就获取异常对象的`value`属性保存到_r,退出循环,恢复委托生成器的运行;
break
RESULT = _r # _r就是整个yield from表达式返回的值。
如果你已经理解了,那么我们继续。现实情况下,yield from要做的事情会复杂一些,毕竟我们做出了一系列的假设。将假设去掉没有什么难度,但是有几个问题非常难受:
- 子生成器可能只是一个迭代器,并不是一个作为协程的生成器,所以它不支持
.throw()和.close()方法; - 如果子生成器支持
.throw()和.close()方法,但是在子生成器内部,这两个方法都会抛出异常; - 调用方让子生成器自己抛出异常,没有原因,就是任性;
- 当调用方使用
next()或者.send(None)时,都要在子生成器上调用next()函数,当调用方使用.send()发送非None值时,才调用子生成器的.send()方法;
这些问题都是yield from结构需要考虑的事情,下面我们来看一下完成的简化之前的代码,相关的注解也写到了注释中:
_i = iter(EXPR) # EXPR是一个可迭代对象,_i其实是子生成器;
try:
_y = next(_i) # 预激子生成器,把产出的第一个值存在_y中;
except StopIteration as _e:
_r = _e.value # 如果抛出了`StopIteration`异常,那么就将异常对象的`value`属性保存到_r,这是最简单的情况的返回值;
else:
while 1: # 尝试执行这个循环,委托生成器会阻塞;
try:
_s = yield _y # 生产子生成器的值,等待调用方`send()`值,发送过来的值将保存在_s中;
except GeneratorExit as _e:
try: # 这部分的作用是关闭子生成器和委托生成器,因为子生成器可能是个可迭代对象,所以要处理没有close()方法的情况;
_m = _i.close
except AttributeError:
pass
else:
_m()
raise _e
except BaseException as _e: # 这部分是处理通过.throw()方法传入的异常,如果子生成器是个迭代器,没有throw()方法的情况下,委托生成器会抛出一个异常
_x = sys.exc_info()
try:
_m = _i.throw
except AttributeError:
raise _e
else: # 子生成器有throw()的情况,那么就调用throw()方法,并且传入调用发提供的异常。这时,子生成器可能会处理异常并继续执行,叶可能会抛出`StopIteration`异常结束执行,也有可能没有处理并且向上"冒泡",抛出异常;
try:
_y = _m(*_x)
except StopIteration as _e:
_r = _e.value
break
else: # 这部分是当子生成器在执行时没有出现异常的情况
try:
if _s is None: # 如果调用方发送的是None,那么就在子生成器上调用next()函数;
_y = next(_i)
else: # 调用发发送的不是None,调用子生成器的.send()方法;
_y = _i.send(_s)
except StopIteration as _e: # 如果出现了StopIteration异常,那么就获取异常对象中value属性的值,并保存在返回值中,中断循环,让委托生成器继续运行
_r = _e.value
break
RESULT = _r # _r就是整个yield from表达式返回的值。
看完代码,我们总结一下关键点:
- 子生成器生产的值,都是直接传给调用方的;调用方通过
.send()发送的值都是直接传递给子生成器的;如果发送的是None,会调用子生成器的__next__()方法,如果不是None,会调用子生成器的.send()方法; - 子生成器退出的时候,最后的
return EXPR,会触发一个StopIteration(EXPR)异常; yield from表达式的值,是子生成器终止时,传递给StopIteration异常的第一个参数;- 如果调用的时候出现
StopIteration异常,委托生成器会恢复运行,同时其他的异常会向上"冒泡"; - 传入委托生成器的异常里,除了
GeneratorExit之外,其他的所有异常全部传递给子生成器的.throw()方法;如果调用.throw()的时候出现了StopIteration异常,那么就恢复委托生成器的运行,其他的异常全部向上"冒泡"; - 如果在委托生成器上调用
.close()或传入GeneratorExit异常,会调用子生成器的.close()方法,没有的话就不调用。如果在调用.close()的时候抛出了异常,那么就向上"冒泡",否则的话委托生成器会抛出GeneratorExit异常。
到这里,整个yield from的执行原理已经搞清楚了,可能在现实中用不太上,但是对于理解Python协程的工作方式还是有一定帮助的。
0x03 在并发和异步之前
我们都知道,CPython解释器这个东西,本身是非线程安全的,存在一个GIL,一次只允许一个线程执行Python代码。而且我们无法通过Python代码来控制GIL,即便有办法,也不是提倡的做法。GIL的存在给我们在编写多线程程序的时候带来了一定程度的困扰。然而实际上,对于I/O密集型任务而言,GIL在某种程度上还会有一些正面作用。
在Python标准库中,所有的I/O阻塞型函数都会释放GIL来允许其他线程运行,除此之外,time.sleep()函数也会释放GIL,这让Python的多线程在I/O密集型任务中还是能发挥一些作用的。例如Python线程在等待网络I/O时,会释放GIL给其他的线程。而对于计算密集型的任务来说,规避GIL的最简单的方法就是使用多进程。
既然在I/O密集的情况下,多线程并没有什么明显的问题,那么为什么还是要推荐使用协程来处理呢?要知道,每种OS中线程的消耗是不一样的,Python使用的线程消耗的内存需要以MB来计算。如果在并发数量很大(连接数量很大)的情况下,例如几万个连接,这样的内存消耗量是非常可怕的。为了解决这种内存消耗大的情况,可以使用回调机制来实现异步调用。调用后立即返回,当某事件发生时,调用我们指定的回调函数,看起来简单粗暴有效,同时带来的副作用就是令人极其难过的"callback hell"。
于是协程式的异步编程就出现了,并且能很好的解决这些问题,极大的提高效率,并且Python原生的支持也并不弱,第三方库的支持也有很多,例如大名鼎鼎gevent和它的猴子补丁。下面我们从一个实际的爬虫问题入手,分别以多线程、协程角度思考,弄明白异步编程的思维方法与传统编程有什么不同。
0x04 一切从爬虫开始
我们从一个简单的爬虫开始,这个爬虫很简单,访问指定的URL,并且获取内容并计算长度,这里我们给定5个URL。第一版的代码十分简单,顺序获取每个URL的内容,当第一个请求完成、计算完长度后,再开始第二个请求。
# filename: spider_normal.py
import time
import requests
targets = [
"https://lightless.me/archives/python-coroutine-from-start-to-boom.html",
"https://github.com/aio-libs",
"https://www.python.org/dev/peps/pep-0380/",
"https://www.baidu.com/",
"https://www.zhihu.com/",
]
def spider():
results = {}
for url in targets:
r = requests.get(url)
length = len(r.content)
results[url] = length
return results
def show_results(results):
for url, length in results.items():
print("Length: {:^7d} URL: {}".format(length, url))
def main():
start_time = time.time()
results = spider()
print("Use time: {:.2f}s".format(time.time() - start_time))
show_results(results)
if __name__ == '__main__':
main()
我们多运行几次看看结果。
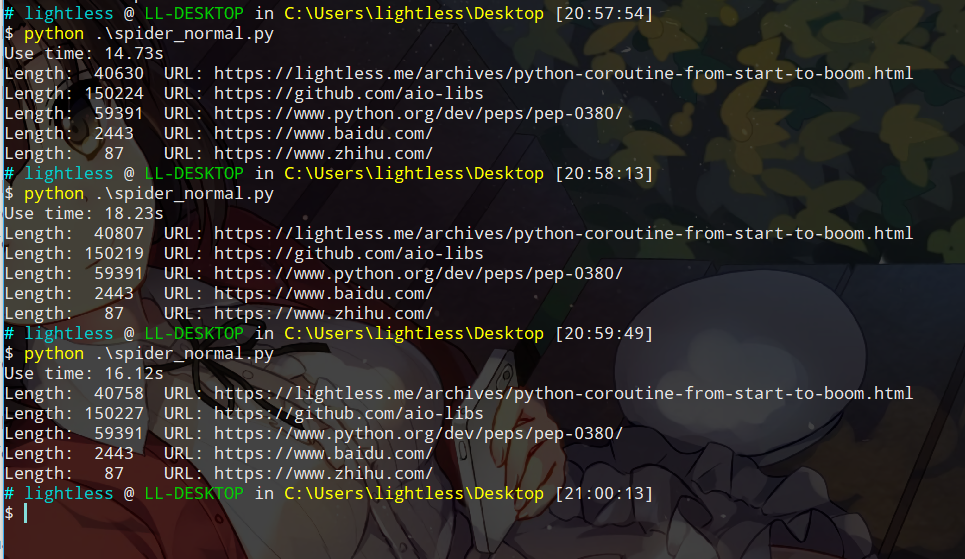
大约需要花费14-16秒不等,这段代码并没有什么好看的,我们把关注点放在后面的代码上。现在我们使用多线程来改写这端代码。
# filename: spider_thread.py
import time
import threading
import requests
from spider_normal import targets, show_results
final_results = {}
def spider(url):
r = requests.get(url)
length = len(r.content)
final_results[url] = length
def main():
ts = []
start_time = time.time()
for url in targets:
t = threading.Thread(target=spider, args=(url, ))
ts.append(t)
t.start()
for t in ts:
t.join()
print("Use time: {:.2f}s".format(time.time() - start_time))
show_results(final_results)
if __name__ == '__main__':
main()
再来看一下结果,很明显,我们的耗时已经降低到10s左右了:
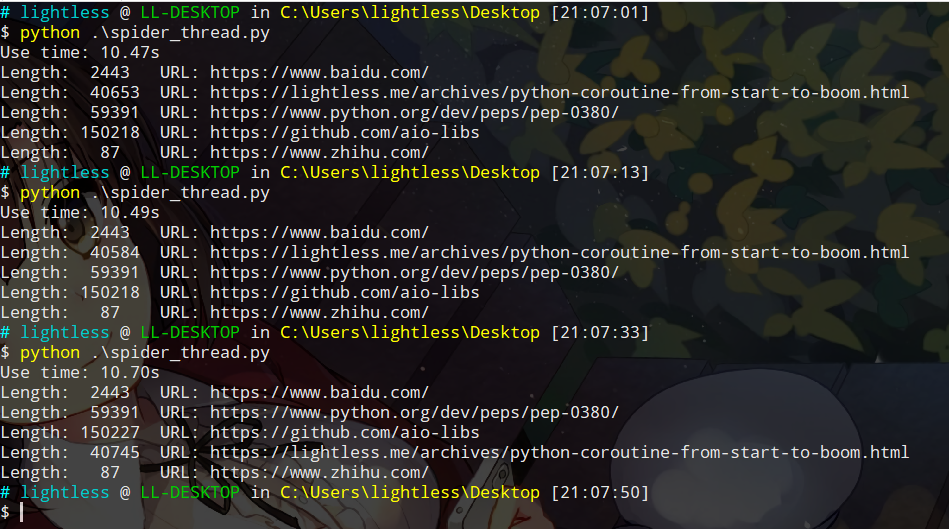
从这两段代码中,已经可以看出并发对于处理任务的好处了,但是使用原生的threading模块还是略显麻烦,Python已经给我们内置了一个处理并发任务的库concurrent,我们借用这个库修改一下我们的代码,之所以修改成这个库的原因还有一个,那就是引出我们后面会谈到的Future。
import time
from concurrent import futures
import requests
from spider_normal import targets, show_results
final_results = {}
def spider(url):
r = requests.get(url)
length = len(r.content)
final_results[url] = length
return True
def main():
start_time = time.time()
with futures.ThreadPoolExecutor(10) as executor:
res = executor.map(spider, targets)
print("Use time: {:.2f}s".format(time.time() - start_time))
show_results(final_results)
if __name__ == '__main__':
main()
执行一下,会发现耗时与上一个版本一样,稳定在10s左右。
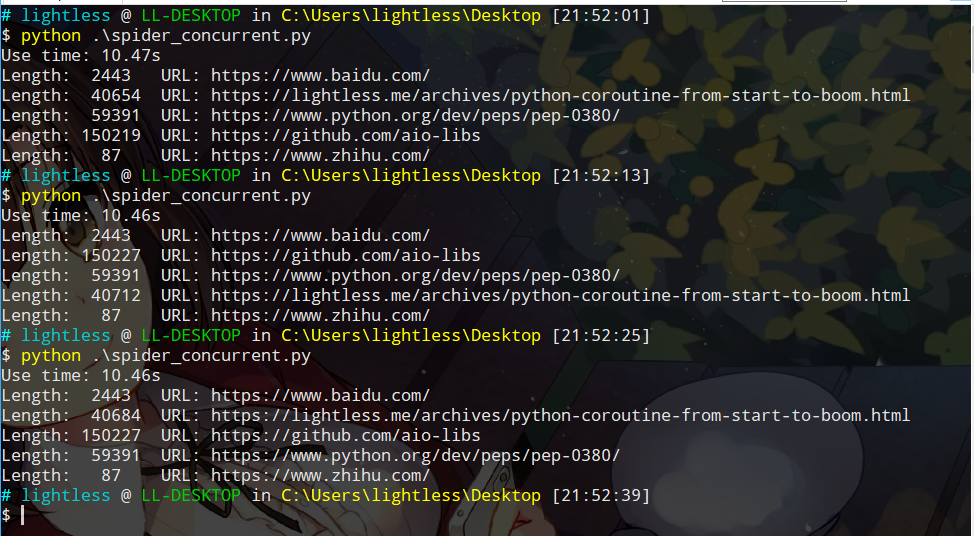
可以看到我们调用了concurrent库中的futures,那么到底什么是futures?简单的讲,这个对象代表一种异步的操作,可以表示为一个需要延时进行的操作,当然这个操作的状态可能已经完成,也有可能尚未完成,如果你写JS的话,可以理解为是类似Promise的对象。在Python中,标准库中其实有两个Future类,一个是concurrent.futures.Future,另外一个是asyncio.Future,这两个类很类似,不完全相同,这些实现差异以及API的差异我们先按下暂且不谈,有兴趣的同学可以参考下相关的文档。Future是我们后面讨论的asyncio异步编程的基础,因此这里多说两句。
Future代表的是一个未来的某一个时刻一定会执行的操作(可能已经执行完成了,但是无论如何他一定有一个确切的运行时间),一般情况下用户无需手动从零开始创建一个Future,而是应当借助框架中的API生成。比如调用concurrent.futures.Executor.submit()时,框架会为"异步操作"进行一个排期,来决定何时运行这个操作,这时候就会生成一个Future对象。
现在,我们来看看如何使用asyncio进行异步编程,与多线程编程不同的是,多个协程总是运行在同一个线程中的,一旦其中的一个协程发生阻塞行为,那么整个线程都被阻塞,进而所有的协程都无法继续运行。asyncio.Future和asyncio.Task都可以看做是一个异步操作,后者是前者的子类,BaseEventLoop.create_task()会接收一个协程作为参数,并且对这个任务的运行时间进行排期,返回一个asyncio.Task类的实例,这个对象也是对于协程的一层包装。如果想获取asyncio.Future的执行结果,应当使用yield from来获取,这样控制权会被自动交还给EventLoop,我们无需处理"等待Future或Task运行完成"这个操作。于是就有了一个很愉悦的编程方式,如果一个函数A是协程、或返回Task或Future的实例的函数,就可以通过result = yield from A()来获取返回值。下面我们就使用asyncio和aiohttp来改写我们的爬虫。
import asyncio
import time
import aiohttp
from spider_normal import targets, show_results
final_results = {}
async def get_content(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as resp:
content = await resp.read()
return len(content)
async def spider(url):
length = await get_content(url)
final_results[url] = length
return True
def main():
loop = asyncio.get_event_loop()
cor = [spider(url) for url in targets]
start_time = time.time()
result = loop.run_until_complete(asyncio.gather(*cor))
print("Use time: {:.2f}s".format(time.time() - start_time))
show_results(final_results)
print("loop result: ", result)
if __name__ == '__main__':
main()
结果非常惊人,鹅妹子嘤!
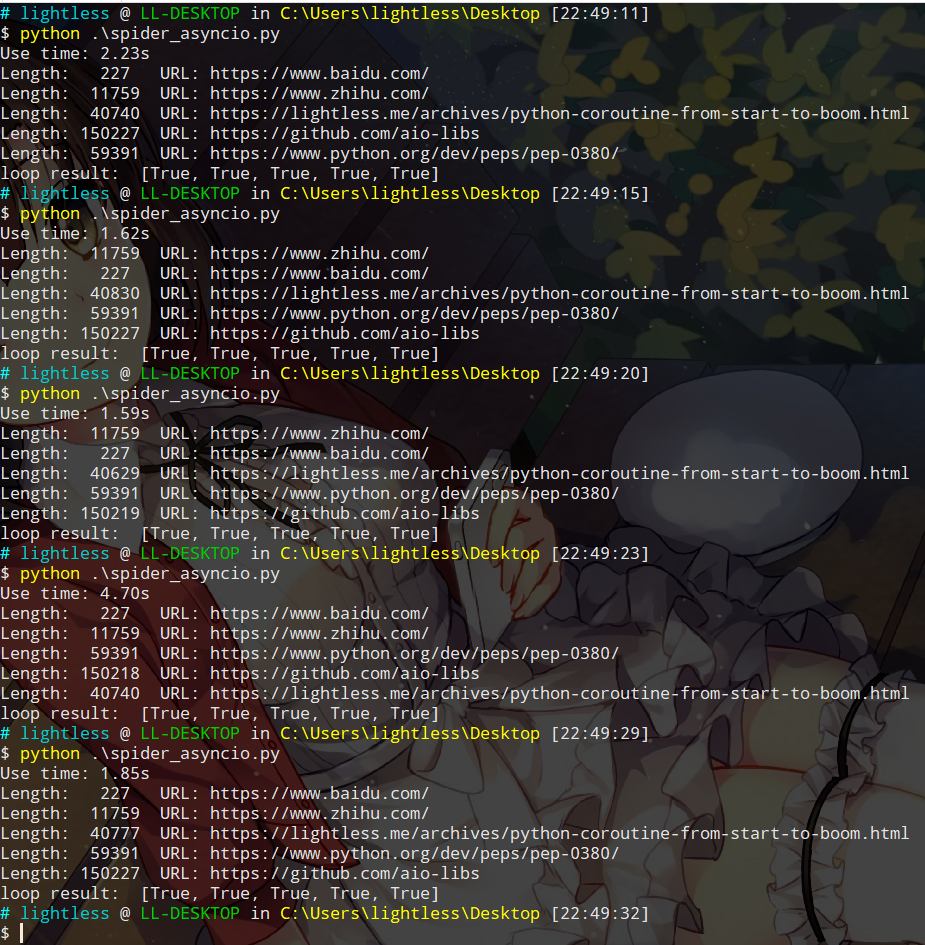
这里可能有同学会问为什么没看到yield from以及@asyncio.coroutine,那是因为在Python3.5以后,增加了async def和awiat语法,等效于@asyncio.coroutine和yield from,详情可以参考上一篇文章。在main()函数中,我们先获取一个可用的事件循环,紧接着将生成好的协程任务添加到这个循环中,并且等待执行完成。在每个spider()中,执行到await的时候,会交出控制权(如果不明白请向前看一下委托生成器的部分),并且切到其他的协程继续运行,等到get_content()执行完成返回后,那么会恢复spider()协程的执行。get_content()函数中只是通过async with调用aiohttp库的最基本方法获取页面内容,并且返回了长度,仅此而已。
在修改为协程版本后,爬虫性能有了巨大的提升,从最初了15s,到10s,再到现在的2s左右,简直是质的飞跃。这只是一个简单的爬虫程序,相比多线程,性能提高了近5倍,如果是其他更加复杂的大型程序,也许性能提升会更多。asyncio这套异步编程框架,通过简单的事件循环以及协程机制,在需要等待的情况下主动交出控制权,切换到其他协程进行运行。到这里就会有人问,为什么要将requests替换为aiohttp,能不能用requests?答案是不能,还是我们前面提到过的,在协程中,一切操作都要避免阻塞,禁止所有的阻塞型调用,因为所有的协程都是运行在同一个线程中的!requests库是阻塞型的调用,当在等待I/O时,并不能将控制权转交给其他协程,甚至还会将当前线程阻塞,其他的协程也无法运行。如果你在异步编程的时候需要用到一些其他的异步组件,可以到https://github.com/aio-libs/这里找找,也许就有你需要的异步库。
关于asyncio的异步编程资料目前来说还不算很多,官方文档应该算是相当不错的参考文献了,其中非常推荐的两部分是:Develop with asyncio和Tasks and coroutines,各位同学有兴趣的话可以自行阅读。asyncio这个异步框架中包含了非常多的内容,甚至还有TCP Server/Client的相关内容,如果想要掌握asyncio这个异步编程框架,还需要多加练习。顺带一提,asyncio非常容易与其他的框架整合,例如tornado已经有实现了asyncio.AbstractEventLoop的接口的类AsyncIOMainLoop,还有人将asyncio集成到QT的事件循环中了,可以说是非常的灵活了。
最后推荐一下《流畅的Python》,这本书中关于协程的部分介绍的非常详细,本文中相当一部分内容都参考自这里,强烈推荐。

看来博主也是动漫爱好者
太二次元了